AI 업무 자동화
Crawl4AI 분석: 블로그 소재 수집과 AI 리서치 자동화에 쓸 수 있을까?
Crawl4AI를 블로그 리서치와 콘텐츠 큐 자동화 후보로 검토하되, robots, 약관, rate limit, 데이터 재사용 권리를 안전 게이트로 둡니다.
핵심 요약
Crawl4AI를 블로그 리서치와 콘텐츠 큐 자동화 후보로 검토하되, robots, 약관, rate limit, 데이터 재사용 권리를 안전 게이트로 둡니다.
Crawl4AI 분석: 블로그 소재 수집과 AI 리서치 자동화에 쓸 수 있을까?
Crawl4AI를 블로그 리서치와 콘텐츠 큐 자동화 후보로 검토하되, robots, 약관, rate limit, 데이터 재사용 권리를 안전 게이트로 둡니다.
이 글은 단순한 도구 추천이 아니라 Biz2Lab / MyBiz 관점에서 Crawl4AI을 실제 업무 자동화 파이프라인에 붙일 수 있는지 검토하는 분석 글입니다. 무료 여부보다 중요한 것은 라이선스, 운영 안정성, 데이터 보안, 반복 작업 감소 효과입니다.
문제 정의
Crawl4AI을 검토하는 이유는 새 도구를 하나 더 늘리기 위해서가 아닙니다. 반복되는 내부 업무를 줄이고, 운영자가 확인해야 하는 데이터와 승인 흐름을 한 화면에서 다룰 수 있는지 판단하기 위해서입니다.
핵심 개념
핵심은 Crawl4AI 자체보다 연결 구조입니다. 데이터 원천, 권한, 승인 화면, 자동화 로그, 예외 처리 기준이 분리되어 있어야 실제 운영에서 안전하게 테스트할 수 있습니다.
현장 시나리오
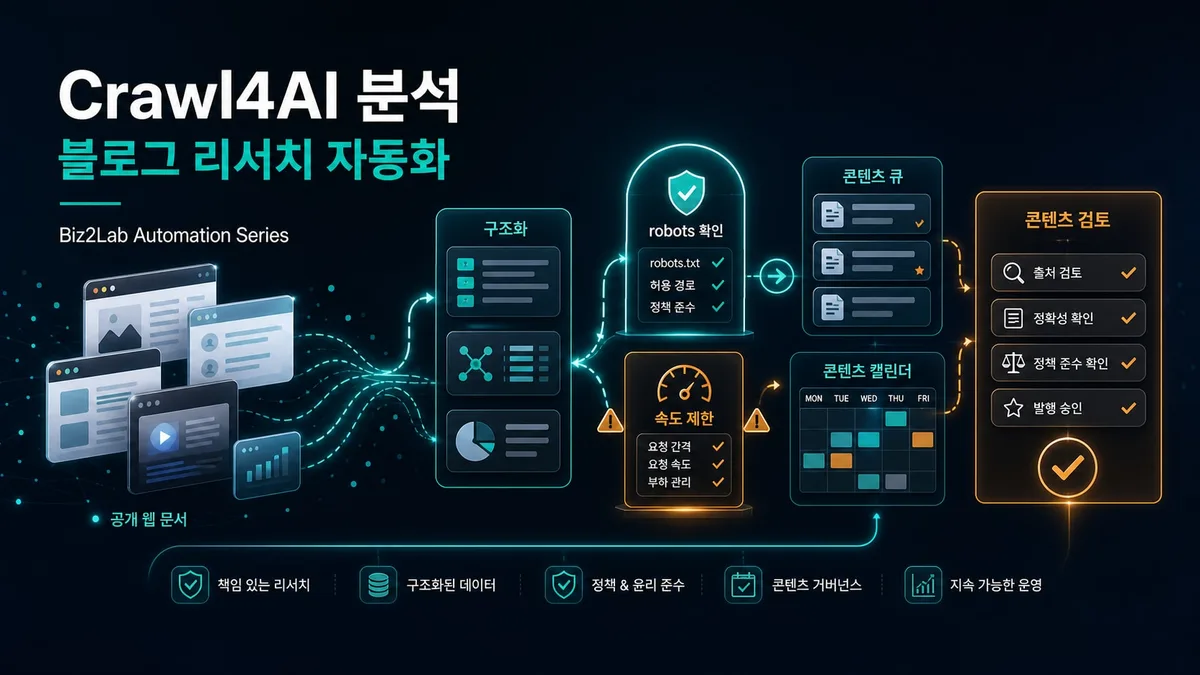
Crawl4AI는 블로그 소재 수집과 AI 리서치 자동화 후보로 볼 수 있지만 무단 스크래핑을 권장하지 않는다.
robots, 서비스 약관, rate limit, 저작권과 재사용 권리를 publication 전에 확인해야 한다.
Biz2Lab에서는 원문 복제가 아니라 공개 출처 확인, 요약 후보, 링크 기반 리서치 큐를 만드는 방향으로 검토한다.
실행 절차
- 공식 문서와 라이선스를 먼저 확인합니다.
- 샘플 데이터로 내부 화면 또는 자동화 흐름을 구성합니다.
- 권한, 로그, 백업, 장애 대응 기준을 검토합니다.
- 실제 고객 데이터 연결은 별도 승인 뒤에 진행합니다.
자동화 구조
입력 데이터, 내부 검토 화면, 승인 액션, 결과 기록을 분리해 설계합니다. 이 구조를 지켜야 Activepieces, Node-RED, Baserow 같은 다른 도구와 연결해도 책임 범위가 흐려지지 않습니다.
리스크와 방지책
가장 큰 리스크는 무료 오픈소스라는 이유로 운영 권한을 너무 빨리 넘기는 것입니다. 테스트 단계에서는 샘플 데이터, 제한 계정, 별도 로그, 백업 계획을 기준으로 검증해야 합니다.
도입 순서
먼저 읽기 전용 대시보드나 내부 검토 화면으로 시작합니다. 이후 반복 작업 감소 효과가 확인되면 승인 버튼, 알림, 외부 시스템 연결처럼 위험도가 높은 기능을 단계적으로 붙이는 편이 안전합니다.
결론부터: 크롤링 남용이 아니라 리서치 큐 검증 도구
Crawl4AI는 블로그 소재 수집과 AI 리서치 자동화 후보로 볼 수 있지만 무단 스크래핑을 권장하지 않는다.
robots, 서비스 약관, rate limit, 저작권과 재사용 권리를 publication 전에 확인해야 한다.
Biz2Lab에서는 원문 복제가 아니라 공개 출처 확인, 요약 후보, 링크 기반 리서치 큐를 만드는 방향으로 검토한다.
콘텐츠 자동화 적용 각도
공식 문서, 공개 릴리스 노트, 제품 페이지 변경을 모니터링해 콘텐츠 후보를 정리하는 흐름을 검토한다.
Huginn은 이벤트 감시, Kestra는 오케스트레이션, Crawl4AI는 수집/정제 단계 후보로 역할을 나눠 본다.
수집한 데이터는 바로 게시하지 않고 사람이 출처와 문맥을 검토하는 승인 게이트를 둔다.
법적·운영 안전 게이트
로그인 뒤 데이터, 유료 콘텐츠, robots로 제한된 경로, 개인 정보가 포함된 페이지는 예시에서 제외한다.
대량 요청, 우회, fingerprint 회피 같은 표현은 쓰지 않는다.
기사에서는 수집 자동화보다 출처 추적, citation, 검토 가능한 리서치 asset화에 초점을 둔다.
공식 출처 확인 포인트
- Crawl4AI documentation - official usage, crawling model, and quick-start verification
- Crawl4AI GitHub repository - source, license, activity, and release verification
- Crawl4AI quick start - example workflow and extraction behavior verification
Biz2Lab / MyBiz 적용 기준
Crawl4AI은 자동화 후보 도구입니다. 다만 고객 데이터, 결제, 외부 메시지, 운영 서버에 직접 연결하는 단계는 별도의 승인과 보안 검토가 필요합니다.
안전 게이트
- Do not encourage scraping that violates robots, terms, authentication, or rate limits.
- Do not collect personal data, paid content, or private pages in examples.
- Treat external crawling at scale as a separate approval-gated implementation.
라이선스 확인 메모
- Verify the current Crawl4AI license and cloud/API terms before publication.
- Separate open-source library use from any hosted or beta cloud service claims.
- Do not imply collected third-party content can be republished without permission.
무료 오픈소스 자동화 도구 시리즈
한 줄 결론은 명확합니다. Crawl4AI은 지금 당장 모든 운영을 맡길 완성형 핵심 도구라기보다, Biz2Lab / MyBiz 자동화 파이프라인에 붙일 수 있는지 검증할 후보 도구입니다.
자주 묻는 질문
Crawl4AI을 바로 실운영 핵심 도구로 써도 되나요?
바로 고정하기보다 로컬 테스트, 권한, 보안, 백업, 라이선스 확인을 거친 뒤 단계적으로 판단하는 편이 안전합니다.
무료 오픈소스라는 이유만으로 상업적 사용이 가능한가요?
아닙니다. 공식 저장소의 현재 라이선스와 hosted 또는 enterprise 약관을 별도로 확인해야 합니다.
Crawl4AI을 자동화 파이프라인에 붙일 때 먼저 확인할 기준은 무엇인가요?
실제 운영 데이터 대신 샘플 데이터로 권한, 로그, 백업, 반복 작업 감소 효과를 먼저 확인해야 합니다.
현장 체크리스트
- Crawl4AI 분석: 블로그 소재 수집과 AI 리서치 자동화에 쓸 수 있을까?에 필요한 입력 자료를 먼저 한곳에 모읍니다.
- 금액, 날짜, 고객명처럼 틀리면 안 되는 항목은 원본과 대조합니다.
- AI 결과는 초안으로 두고 사람이 마지막으로 확인합니다.
- 관련 글과 다음 단계를 연결해 후속 업무가 끊기지 않게 합니다.
관련 글
무료 오픈소스 자동화 도구 실전 분석: 소상공인·블로거·SaaS 운영자를 위한 도구 지도
무료 오픈소스 자동화 도구를 단순 추천이 아니라 실제 업무 자동화, 콘텐츠 제작, 데이터 자산화, SaaS 운영 관점에서 검증합니다.
NocoDB 분석: Airtable 대체 도구로 쓸 수 있을까? 라이선스와 운영 리스크 검토
NocoDB를 Airtable 대체 데이터베이스 자동화 후보 관점에서 분석합니다. 라이선스, 셀프호스팅, 업무 자동화 적용 가능성과 운영 리스크를 함께 검토합니다.
Activepieces 분석: n8n 대안이 될 수 있는 AI 업무 자동화 도구
Activepieces를 n8n, Zapier 대안 관점에서 분석합니다. AI 자동화, MCP, 오픈코어 라이선스, 소상공인 업무 자동화 적용 가능성을 정리했습니다.
OpenCut 분석: 무료 오픈소스 영상 편집기, AI 콘텐츠 자동화에 쓸 수 있을까?
OpenCut을 무료 CapCut 대체재가 아니라 AI 콘텐츠 자동화 후보 도구로 분석합니다. 장점, 리스크, 쇼츠 자동화 적용 가능성을 정리했습니다.
다음 단계
반복 업무와 콘텐츠 제작 흐름을 실제 운영 기준으로 점검합니다.
자동화 상담 문의오픈소스 자동화 도구 검증 체크리스트
다운로드 시스템은 구글 애드센스 승인 이후 단계로 두고, 현재는 글 안에서 점검 기준을 먼저 제공합니다.